李沐老师实用机器学习笔记: Machine Learning Model
3.1 机器学习模型概览 ML Model Overview
?️ 授课视频:
授课视频【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
? 课件:
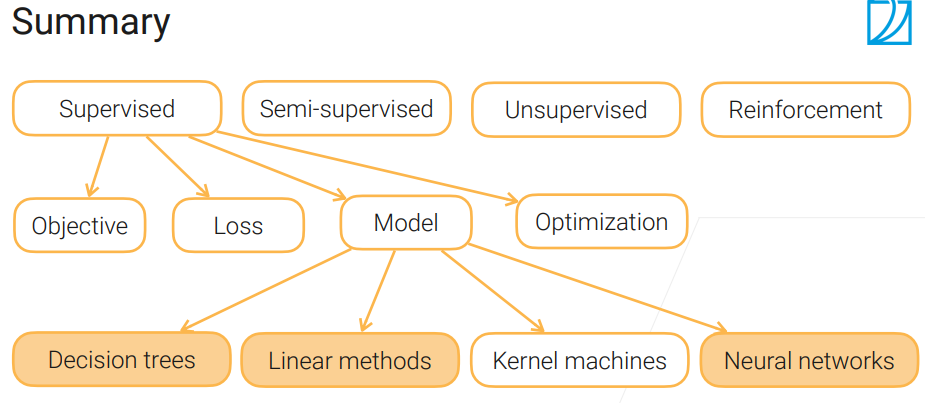
机器学习算法的类型
- 监督学习:有label的训练数据 (最常使用)
- 半监督学习:有label和无label的数据都用来训练,例如,self-trianing
- 无监督学习:使用无label的数据进行训练,例如,聚类,密度估计
- 强化学习:使用交互式的观测,最大化奖惩
监督学习的元素
- 模型:有一系列可以训练的参数,能把输入映射为输出
- 损失函数(loss):测量模型的输出和实际label的差距
- 目标(objective): 优化模型的目标,例如,最小化loss
- 优化(optimization):用来实现目标的算法,例如,SGD
3.2 决策树
?️ 授课视频:
授课视频【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
? 课件:
这里课程介绍的很简洁,详细的介绍请参考我们的文章 (Wan-Chi Siu, Xue-Fei Yang, Li-Wen Wang, Jun-Jie Huang and Zhi-Song Liu, “Introduction to Random Tree and Random Forests for fast signal processing and object classification,” Learning Approaches in Signal Processing, W.-C. Siu, L.-P. Chau, L. Wang and T. Tan, eds., pp. 27-76: Pan Stanford Series on Digital Signal Processing, 2018.)
决策树有两种类型:
- 分类树:输出类别
- 回归树:输出预测的数值
决策树节点的分类:
- 父节点:有子节点
- 叶子节点:没有子节点
容易训练和调优,在工业界经常使用
对数据敏感:可以使用ensemble learning
决策树的构建
- 自顶至下的构建方式
- 在每一个父节点,选择一个特征区分样本
决策树的缺点
- 过于复杂的树会过拟合:深度太深
- 对数据敏感:改变一部分数据,重新训练可能会改变树的结构
- 不容易并行计算
随机森林
- 训练多个决策树提升鲁棒性:树与数之间不行独立,可以并行处理。最终的决策由投票决定
- 随机性来自于(1)训练样本抽样bagging,(2)随机选择一部分特征进行训练
3.3 线性模型
?️ 授课视频:
授课视频【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
? 课件:
模型-线性回归: $y=w_1x_1+w_2x_2+…+w_nx_n+b$ 其中$w$and$b$ 是可以学习的参数
目标:最小化均方误差
损失函数:L2-norm loss
优化方法:随机梯度下降
3.4 神经网络
?️ 授课视频:
授课视频【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
? 课件:
与传统机器学习的关系
手工特征(传统机器学习)⇒ 可以学习的特征提取器(深度学习,神经网络)
线性模型(传统机器学习) ⇒ 多层感知机 (神经网络, linear regression+activation function)
Q: 为什么要引入activation function(激活层)
A: 多层线性层叠加还是线性层。因此引入非线性元素(激活层)可以提升模型的复杂度(学习能力)。
卷积神经网络CNN
- 节省参数
- 参数共享:同一个模式可以在图片上不同的位置使用
卷积神经网络的构成:
- 卷积层:$k\times k$ 可以学习的核函数
- 池化层(汇聚层):整合一个小的区域的特征,增加位置的鲁棒性
递归神经网络RNN
更好的处理序列信号,通常情况下,我们使用Gated RNN, 例如 LSTM,GRU
模型的选择
- 表格数据:可以使用决策树,线性模型
- 语言或文本:RNN 或者 Transformer
- 图像/语音/视频:CNN,transformer等