李沐老师实用机器学习笔记: Model Combination
5.1 方差和偏差
5.2 Bagging
5.3 Boosting
5.4 Stacking
模型整合(Model Combination)
授课材料
?️ 授课视频:
授课视频【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
- 5.1 方差和偏差
- 5.2 Bagging
- 5.3 Boosting
- 5.4 Stacking
? 课件:
讲义下载地址
7 – Model Combination
- Bias and variance
- Bagging
- Boosting
- Stacking
偏差(bias)和方差(variance)
定义
泛化误差可分解为偏差、方差与噪声之和。
-
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了算法本身的拟合能力。
-
方差度量了同样大小的训练集的变动所导致的学习性能变化,即刻画了数据扰动所造成的影响。
-
噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
偏差度量的是单个模型的学习能力,而方差度量的是同一个模型在不同数据集上的稳定性。
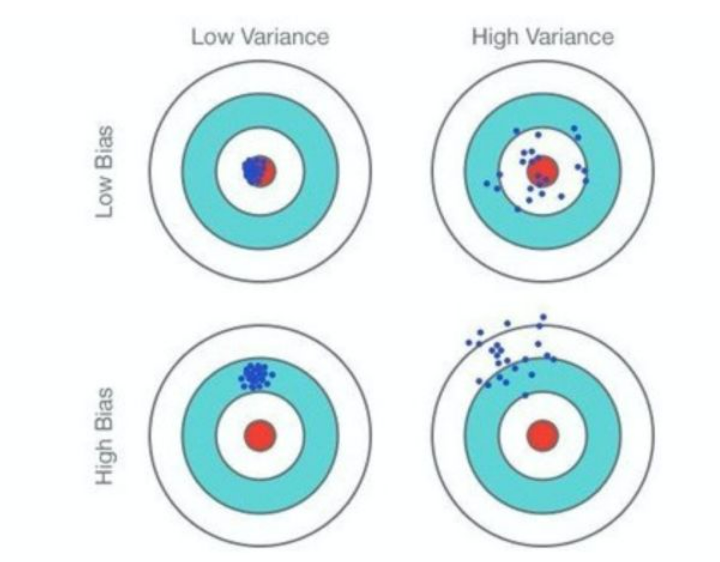
设计机器学习模型时,我们需要考虑:
-
准。bias表示模型相对真实模型的差异。想要低bias,需要复杂化模型,增加参数,但是容易过拟合造成high variance。low bias对应的是所有的点打在了靶心附近,但是不一定集中
-
稳。variance表示的是不同数据集对应的模型之间的差异。想要低variance,需要简化模型,减少参数,但是容易欠拟合造成high bias。low variance对应的是所有的点打的比较集中,但是不一定在靶心附近
数学分解

对于一个数据集 $D$, 我们想学习机器学习模型 $f(\cdot)$, 去拟合真实数据$y=f(x)+\varepsilon$ , $\varepsilon$代表了噪声。
我们用均方误差来表征泛化误差。
可以得到泛化误差来自于偏差,方差和噪声。
与过欠拟合的关系
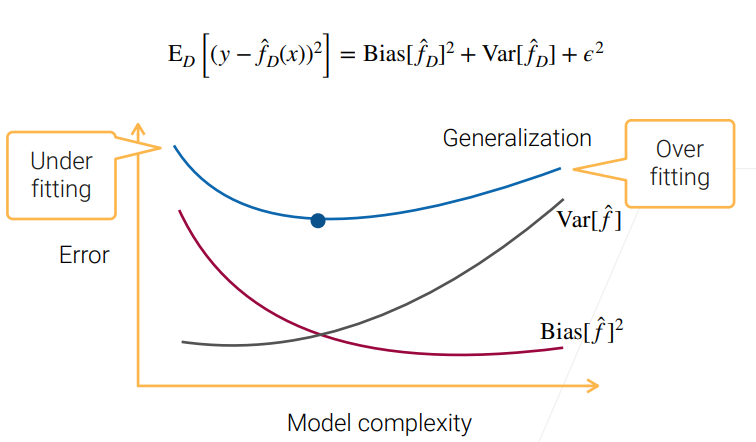
模型越复杂,学习能力越强,与数据的偏差越小,能够学到的方差越大,泛化误差先减小(欠拟合)后增大(过拟合)。
因此,为了获得更小的泛化误差,我们可以:
- 减小偏差:用大模型,或者提高模型学习能力
- 减小方差:用简化的模型(regularization)
- 甚至可以减小噪音:提高数据的质量(数据采集过程的优化,数据预处理等)
装袋算法(Bagging)
Bagging算法 (英语:Bootstrap AGGregatING,引导聚集算法),又称装袋算法,是机器学习领域的一种团体学习算法。
对于一个有m个样本的数据集,每一次训练,有放回的选取m个数据组成新的数据集,有大约$1-1/e\approx 0.63$的数据被使用。
重复n次,训练得到n个模型。
测试时,平均这n个模型的结果
使用bagging可以有效地降低模型的方差,尤其是对于不稳定的学习器。

Boosting
提升方法(Boosting),是一种可以用来减小监督式学习中偏差的机器学习算法。
与Bagging并行使用不同的模型 不同,Boosting顺序使用不同的模型。例如Gradient boosting,后一个模型学习前一个模型的预测的残差。 一个应用时Gradient Boosting Decision Trees (GBDT)
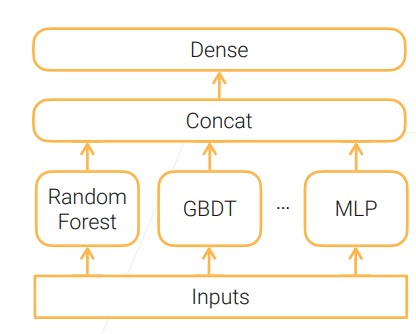
Stacking
https://blog.csdn.net/zmc1248234377/article/details/123396177
stacking 就是将一系列模型(也称基模型)的输出结果作为新特征输入到其他模型,这种方法由于实现了模型的层叠,即第一层的模型输出作为第二层模型的输入,第二层模型的输出作为第三层模型的输入,依次类推,最后一层模型输出的结果作为最终结果。