李沐老师实用机器学习笔记: Data III
2.2 数据清理
数据往往不是完美的,经常存在很多错误,包括 丢失某些特征,异常值等, 好的机器学习模型应该容忍这些错误。
使用存在错误的数据训练模型,模型可能会收敛,但会影响精度和训练速度,而且,对于新收集的数据,也可能带来不利的影响。
因此,应当数据应该尽可能的干净。
?️ 授课视频:
2.2 数据清理【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
? 课件:
数据错误的类型
- Outliers 离群值: 某一些值与其他的观测值显著不同
- 违背规则:例如,价值应当大于0
- 违背模式:例如,singlefamily 写成了 singlefamily, 中间多了
找出数据中存在的错误的方法
-
异常值检测
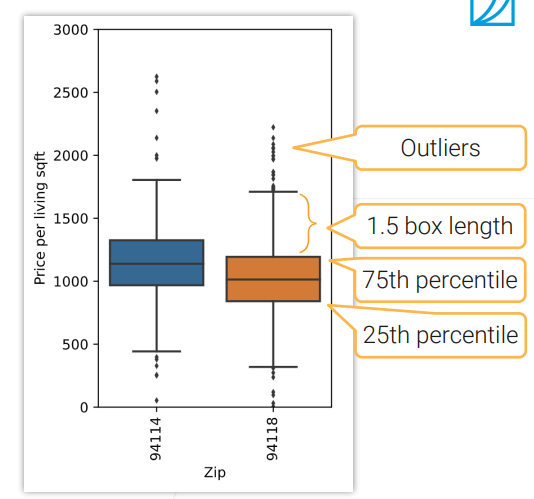
对于异常值的检测,我们可以使用boxplot。首先我们找出中值,并计算出25~75%的区间。在图上,这个区间是蓝色或棕色的矩形。我们找出上下1.5倍矩形框之外的值,这些值通常情况下是有问题(错误)的值。

-
基于规则的检测
我们可以制定规则来找出错误,
依赖性约束:基于邮编,我们可以验证城市名称。基于纳税号,我们可以验证公司名称
拒绝性(Denial)约束:例如,如果有纳税号,电话号码通常不为空 -
基于模式的检测
句法模式:例如检测到eng(简写),我们就知道此项应该为English 字符。
语义模式:国家应该有首都,如果国家检测到斯坦福,斯坦福没有首都,因此无效
我们通常情况下可以使用图形化界面帮助我们指定规则,这里可以使用数据工程师常用的软件,例如Trifacta(如果需要使用的话,需要进一步学习)。
2.2 数据变换
机器学习算法需要固定长度,条件固定,理想分布的输入数据。这要求了我们需要提前预处理数据。
?️ 授课视频:
2.3 数据变换【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
? 课件:
实数值
- 归一化0到1
- 高斯分布
- 10倍压缩,压缩所有值到0-1
- 指数压缩

图片变换
- 裁剪(crop)
- 下采样(尺寸压缩)
- 压缩,中等压缩率(80%-90%)的jpeg压缩大约会带来1%的ImageNet精度损失
- 图片的白化(whitening),图片里很多像素没用,可以通过类似于PCA的方法降维,可能会帮助收敛
视频变换
受限于存储,读取速度
- 一般切片,用<10s 以内的片段
- 视频帧做抽样
文本变换
- Stemming and Lemmatization (词形还原)
am is are ⇒ be, 去掉复数形式。语法对于语义影响不大 - Tokenization,把问题变成一系列的token,根据单词、字符划分
总结
数据变换最主要的考量是,平衡存储、质量、读取速度。
2.4 特征工程
神经网络通常需要固定长度的数据
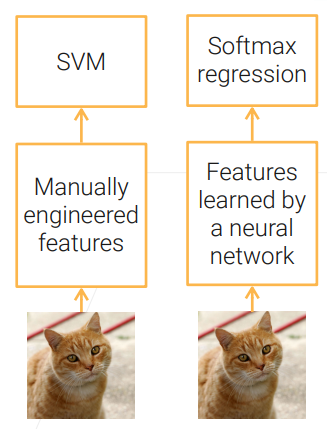
在深度学习之前,我们通常人工提取特征,比如图片里的HOG特征,SIFT特征等。现在,我们直接使用深度学习,让它自己去学习特征提取。
?️ 授课视频:
2.4 特征工程【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
? 课件:
数值数据
- bin,不同的值,使用区间进行划分,类似于HOG
- 独热编码
- 时间类型的数据做维度增广,[year, month, day, day_of_year, week_of_year, day_of_week]
- 特征组合
文本特征
- bag of words, 统计单词出现的次数。丢失语义信息
- word embedding: 使用小的训练模型,对文本进行编码
- 或者使用预训练的深度学习模型,类似于bert
图片或者视频特征
- 传统的特征提取器:sift, hog
- 预训练的深度学习模型:VGG
使用预训练的深度学习模型会更好,但需要更多的计算时间
总结
?️ 授课视频:
2.4 数据科学家的日常【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
? 课件:
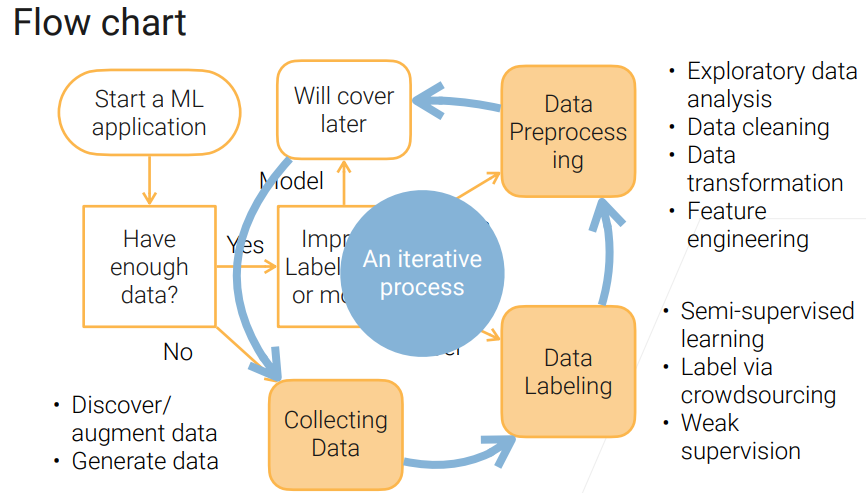
在拿到一个机器学习任务,我们首先要看是不是有充足的数据。如果没有的话,需要去收集或者生成。如果有的话,可能需要去清洗数据,提升数据质量。
对于数据的处理,是一个长期循环的过程。需要收集数据,数据清洗,数据变换(变成想要的类型),然后再训练模型。根据实际结果,根据反馈,再去收集数据。