李沐老师实用机器学习笔记: Data II
1.3 网页数据的抓取
网页数据的抓取是获取训练数据的一个重要的方式。与爬虫不同,数据抓取是为了获取特定的信息,而非爬取整个网页的内容。
?️ 授课视频:
1.3 网页数据抓取【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
? 课件:
工具
- 通常情况下,网站都会有防护措施,防止机器爬取数据。因此我们一般要使用 headless browser 像selenium。
- 而且,我们还需要大量的IP,一旦ip被禁止,我们可以换IP继续抓取数据。
案例学习
房屋价格的抓取 (省略),使用云平台,可以方便的更换ip,而且机器要求不高,价格不贵。
法律问题
- 数据抓取本身并不违法
- 但是,我们要避免抓取敏感数据:(1)需要登陆才能访问的数据,一般比较敏感。(2)不要爬取有版权的信息,(3)网站声明不允许爬取。
- 如果用做商业用途请咨询律师
1.4 数据标注
?️ 授课视频:
1.4 数据标注【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
? 课件:
流程图
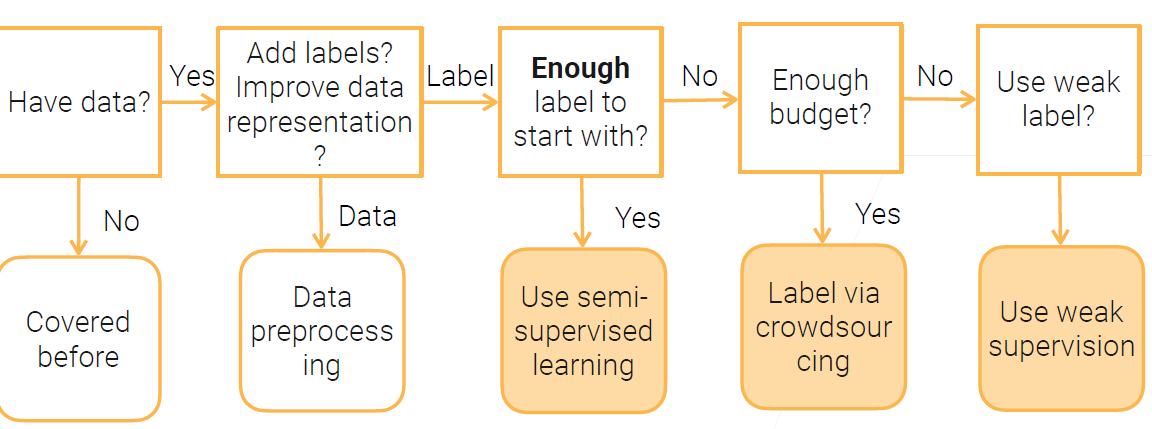
只有部分标签,没钱,不想人工标注数据:半监督学习
如果仅有一小部分的数据,可以使用半监督学习进行数据标注。这里我们的假设是:
- 数据有连续性:拥有相似特征的样本有相同的标签
- 聚类性:数据有聚类的特性,同一类有相同的标签
- 流体假设:数据的复杂度比输入的维度要小
自学习
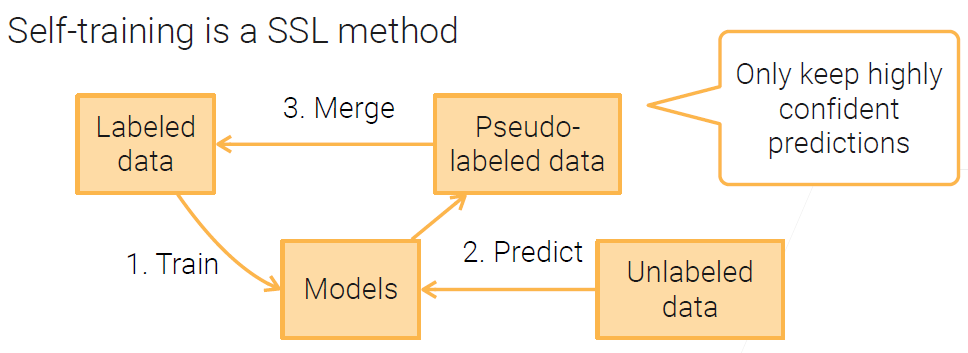
首先,我们先用有限的标签训练一个模型。然后,我们用模型去预测未标记的数据,对于高置信的预测样本,我们把他们融合到标记的数据中,再继续训练我们的模型。
这里我们可以使用更深的模型,或者多个模型做集合预测。因为这里的深度学习模型只是用来打标签,并不会用来实际部署。
只有部分标签,不差钱,可以标注数据:众包标注
可以使用类似于Amazon Mechanical Turk的众包平台,人工标记大量数据。需要注意的是:
- 用户标注页面要尽可能地简单:越简单,对标记人员的要求越低,就可以找到更多的标记人员,就可以拿到更低的价格。比如,对于一个365类的分类问题,可以简化为365个二分类问题,标注人员只需要回答是或者否。
- 花费
- 质量控制:不同标注人员标注的质量不同
主动学习
对自学习进行升级,引入标记人员,进行主动学习。
- 学习那些更不确定的样本(现有知识难以理解,信息多)。
- 学习那些多模型预测不一致的样本 (多样性,信息多)。
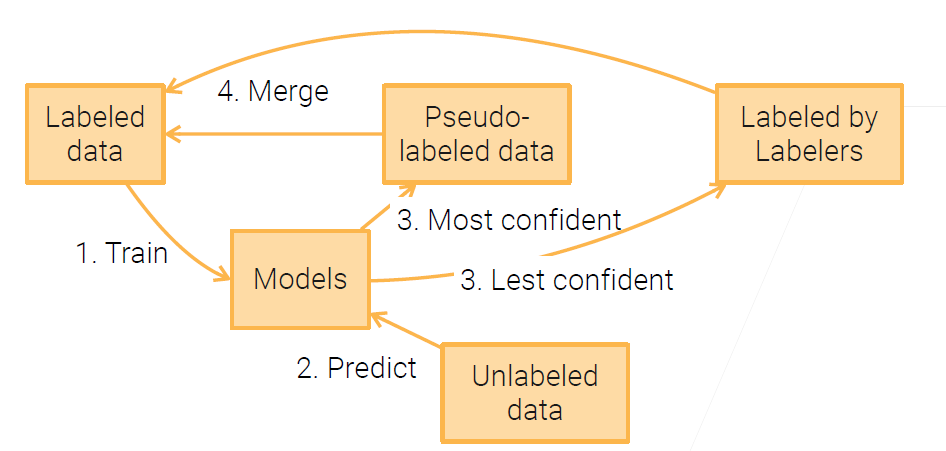
这里,和自学习不同的地方在于:自学习,对于不确定的样本不做处理;主动学习,需要挑出最有代表性的不确定性的样本,进行标注。
质量控制
标注工人经常会犯错。
最简单的办法是:同一样本,多人多次标注,但花费更多。
解决办法:只对有异议的样本(比如,两人不一致的样本)进行多人标注,雇佣高质量的标注员工。
只有部分标签,没钱,想获得监督信号:弱监督学习
定义一些启发性的规则(heuristic programs),来过滤样本,进而产生一些标签,这些标签通常是比人工标记要差,但可以训练模型。
比如在评论分类(人评论的,机器评论的)模型里:对大量的评论可以通过查找关键词,使用其他模型(情绪模型)做预测,来找出最像 “人的评论” 和 “机器的评论。”