BoTNet (2021-01): 将 Self-Attention 嵌入 ResNet
文章:Bottleneck Transformers for Visual Recognition
论文: https://arxiv.org/abs/2101.11605
摘要: We present BoTNet, a conceptually simple yet powerful backbone architecture that incorporates self-attention for multiple computer vision tasks including image classification, object detection and instance segmentation. By just replacing the spatial convolutions with global self-attention in the final three bottleneck blocks of a ResNet and no other changes, our approach improves upon the baselines significantly on instance segmentation and object detection while also reducing the parameters, with minimal overhead in latency. Through the design of BoTNet, we also point out how ResNet bottleneck blocks with self-attention can be viewed as Transformer blocks. Without any bells and whistles, BoTNet achieves 44.4% Mask AP and 49.7% Box AP on the COCO Instance Segmentation benchmark using the Mask R-CNN framework; surpassing the previous best published single model and single scale results of ResNeSt evaluated on the COCO validation set. Finally, we present a simple adaptation of the BoTNet design for image classification, resulting in models that achieve a strong performance of 84.7% top-1 accuracy on the ImageNet benchmark while being up to 1.64x faster in compute time than the popular EfficientNet models on TPU-v3 hardware. We hope our simple and effective approach will serve as a strong baseline for future research in self-attention models for vision
参考文章:
https://zhuanlan.zhihu.com/p/351990004
https://mp.weixin.qq.com/s/KJgeYAQhVZbSeOBxUnJv5g
传统的卷积操作能够有效的捕获 local information, 但是有很多视觉任务(比如物体检测,关键点检测等)需要对 long-range dependency 进行处理。自注意力(self-attention)是一项很传统的计算操作,能够对pairwise entity interactions 进行计算, 因此在自然语音处理(NLP)领域有广泛的应用。
结构设计
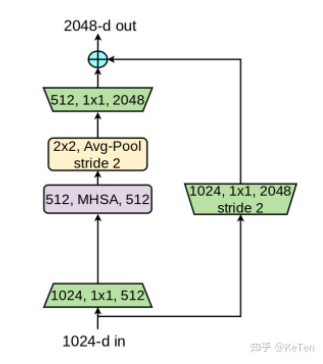
BoTNet提出引入multi-head self-attention (MHSA) 的 bottleneck。两者唯一的不同在于 ResNet使用的是 3×3 的卷积, 而BoTNet提出新的Bottleneck Transformer(BoT)使用 MHSA 替代 3×3 的卷积。
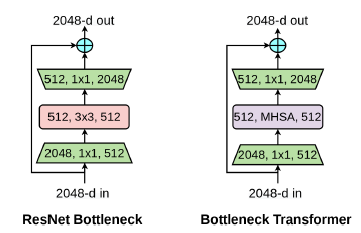
问题/难点:self-attention所需要的内存和计算量是空间维度上的二次方,self-attention when performed globally across n entities requires O(n2d) memory.
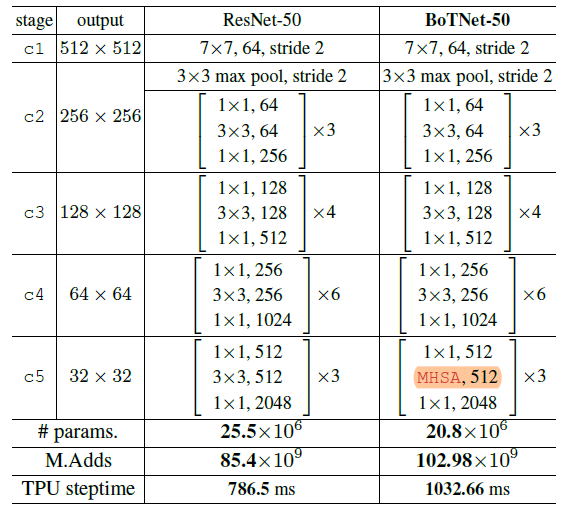
解决方案: 因此,本文提出,将BoT与ResNet相结合。 首先使用ResNet将spatial尺寸降低到32×32 (即c5层)。然后将ResNet Bottleneck 中的3×3卷积替换为BoT。而ResNet-50和BoTNet-50的区别,唯一的不同就在c5的MHSA。而且BoTNe-50t的参数量只有ResNet-50的0.82倍,但是steptime略有增加(主要是因为MHSA需要少的参数,但矩阵叉乘需要更多的计算量)。
MHSA设计
跟Transformer中的multi-head self-attention非常相似,区别在于MSHA将position encoding当成了spatial attention来处理,嵌入两个可学习的向量看成是横纵两个维度的空间注意力,然后将相加融合后的空间向量于q相乘得到contect-position(相当于是引入了空间先验),将content-position和content-content相乘得到空间敏感的相似性feature,让MHSA关注合适区域,更容易收敛。另外一个不同之处是MHSA只在蓝色块部分引入multi-head。(Ref: https://mp.weixin.qq.com/s/KJgeYAQhVZbSeOBxUnJv5g)
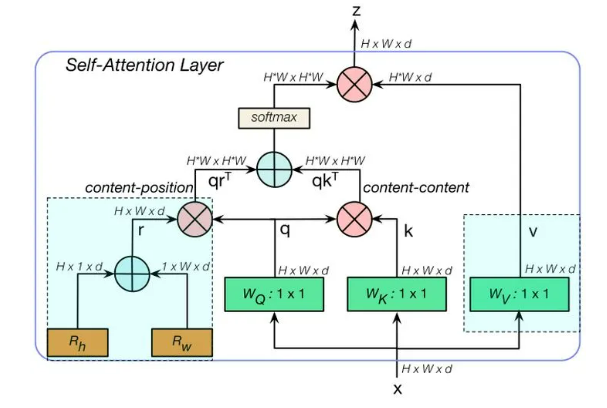
MHSA的位置编码(position encoding)部分,与Transformer不一样的地方在于,由于图像是一个二维的信息,位置编码也是二维的,而不是一维,由Rh和Rw分别代表垂直和水平方向上的相对信息。另一个不同点在于,Transformer的位置编码是MHSA层之前嵌入的,而这篇文章的作者并没有采用一贯的做法。(Ref: https://zhuanlan.zhihu.com/p/351990004)
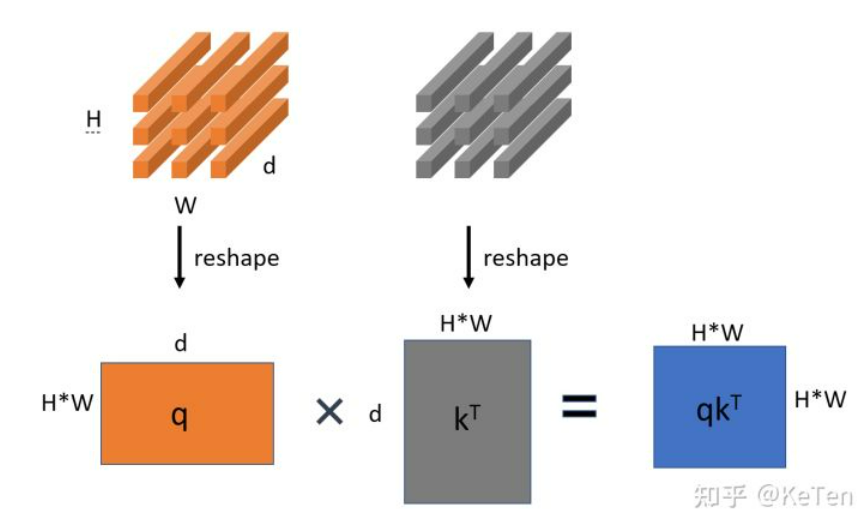
但是由于self-attention并不是一个可以stride的操作,于是如果stride为2,那么需要加入一个avg-pool来完成这个操作. (Ref: https://zhuanlan.zhihu.com/p/351990004)
代码实现(MHSA)
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14):
super(MHSA, self).__init__()
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.rel_h = nn.Parameter(torch.randn([1, n_dims, 1, height]), requires_grad=True)
self.rel_w = nn.Parameter(torch.randn([1, n_dims, width, 1]), requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, C, -1)
k = self.key(x).view(n_batch, C, -1)
v = self.value(x).view(n_batch, C, -1)
content_content = torch.bmm(q.permute(0, 2, 1), k)
content_position = (self.rel_h + self.rel_w).view(1, C, -1).permute(0, 2, 1)
content_position = torch.matmul(content_position, q)
energy = content_content + content_position
attention = self.softmax(energy)
out = torch.bmm(v, attention.permute(0, 2, 1))
out = out.view(n_batch, C, width, height)
return out