Revisiting Global Statistics Aggregation for Improving Image Restoration (消除图像复原中的“misalignment”,性能大幅提升)
Paper: Revisiting Global Statistics Aggregation for Improving Image Restoration (AAAI 2022)
arXiv:https://arxiv.org/pdf/2112.04491.pdf
Code: https://github.com/megvii-research/tlsc
Reference: [1] 消除图像复原中的“misalignment”,性能大幅提升 https://mp.weixin.qq.com/s/HRm6wPDBeopsmLtilF5K-A
[2] https://xiaoqiangzhou.cn/post/chu_revisiting/
问题的提出:
Specifically, with the increasing size of patches for testing, the performance increases in the case of UNet while it increases and
then decreases in UNet-IN and UNet-SE cases.
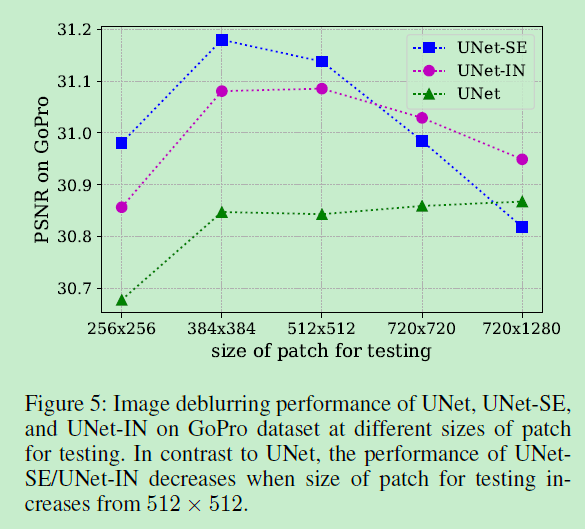
对于一个训练好的UNet模型,使用patch作为测试输入时,随着输入尺寸的增加,性能会变好 (comment:消除了边界效应,更好的边界信息融合)。但是,如果UNet中包含了IN (Instance Norm, 对spatial 平面做归一化) 或者SE (Channel Attention/ Squeeze-and-Excitation, 中间包含了global average pooing, 对spatial平面做平均),增加输入的尺寸,性能先升后降。这就表明,对现有的模型,“训练是patch,测试是全图,使用IN和SE的策略” 存在问题。
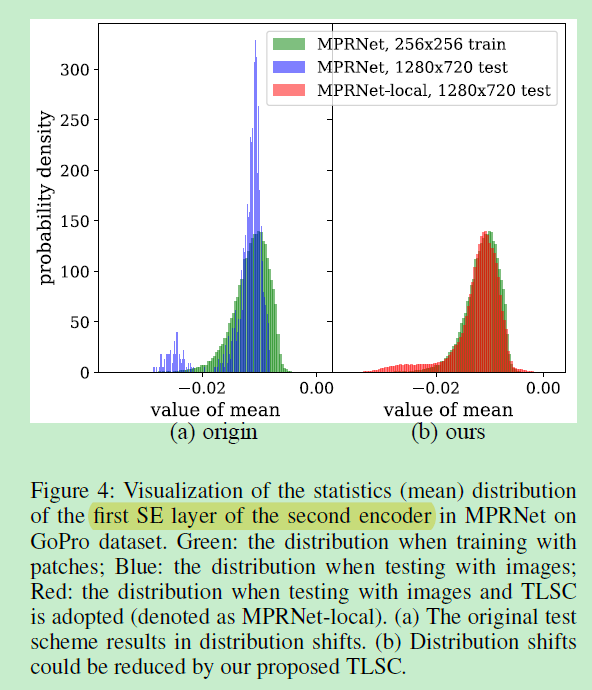
训练与测试阶段的不同全局统计聚合计算方式就导致了"misalignment",即出现了统计分布不一致现象。[1]
训练/测试阶段的基于图像块/完整图像特征的统计聚合计算差异会导致不同的分布,进而导致图像复原的性能下降(该现象被广泛忽视了)。
为解决该问题,我们提出一种简单的TLSC(Test-time Local Statistics Converter)方案,它在测试阶段的区域统计聚合操作由全局替换为局部。无需重新训练或微调,所提方案可以大幅提升已有图像复原方案的性能。[1]
解决方案
以SE为例,原本的global average pooling做法:
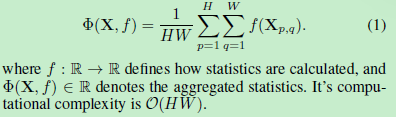
改进后,local statistics calculation 做法。每一个像素都在一个local的区域内(大小等于训练时的尺寸)去做平均。

- 对于边缘像素,复制padding,再做local statistics calculation
- 方法在论文中被拓展到Instance Norm
实验结果
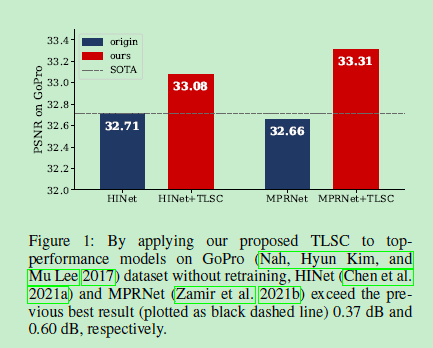
原始的HiNet包含InstanceNorm,使用提出的方法后,性能获得提升。
原始的MPRNet包含SE模块,使用提出的方法后,性能获得提升。
数据分布的提升。
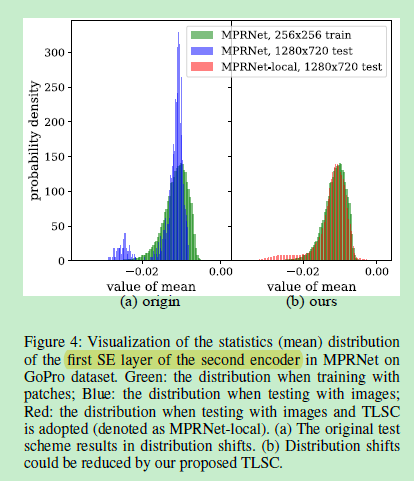
Another observation
Full-image training causes severe performance loss in low-level vision task. This is explained by that full-images training lacks cropping augmentation [2].
代码
# ------------------------------------------------------------------------
# Copyright (c) 2021 megvii-model. All Rights Reserved.
# ------------------------------------------------------------------------
"""
## Revisiting Global Statistics Aggregation for Improving Image Restoration
## Xiaojie Chu, Liangyu Chen, Chengpeng Chen, Xin Lu
"""
import torch
from torch import nn
from torch.nn import functional as F
from basicsr.models.archs.hinet_arch import HINet
from basicsr.models.archs.mprnet_arch import MPRNet
train_size=(1,3,256,256)
class AvgPool2d(nn.Module):
def __init__(self, kernel_size=None, base_size=None, auto_pad=True, fast_imp=False):
super().__init__()
self.kernel_size = kernel_size
self.base_size = base_size
self.auto_pad = auto_pad
# only used for fast implementation
self.fast_imp = fast_imp
self.rs = [5,4,3,2,1]
self.max_r1 = self.rs[0]
self.max_r2 = self.rs[0]
def extra_repr(self) -> str:
return 'kernel_size={}, base_size={}, stride={}, fast_imp={}'.format(
self.kernel_size, self.base_size, self.kernel_size, self.fast_imp
)
def forward(self, x):
if self.kernel_size is None and self.base_size:
if isinstance(self.base_size, int):
self.base_size = (self.base_size, self.base_size)
self.kernel_size = list(self.base_size)
self.kernel_size[0] = x.shape[2]*self.base_size[0]//train_size[-2]
self.kernel_size[1] = x.shape[3]*self.base_size[1]//train_size[-1]
# only used for fast implementation
self.max_r1 = max(1, self.rs[0]*x.shape[2]//train_size[-2])
self.max_r2 = max(1, self.rs[0]*x.shape[3]//train_size[-1])
if self.fast_imp: # Non-equivalent implementation but faster
h, w = x.shape[2:]
if self.kernel_size[0]>=h and self.kernel_size[1]>=w:
out = F.adaptive_avg_pool2d(x,1)
else:
r1 = [r for r in self.rs if h%r==0][0]
r2 = [r for r in self.rs if w%r==0][0]
# reduction_constraint
r1 = min(self.max_r1, r1)
r2 = min(self.max_r2, r2)
s = x[:,:,::r1, ::r2].cumsum(dim=-1).cumsum(dim=-2)
n, c, h, w = s.shape
k1, k2 = min(h-1, self.kernel_size[0]//r1), min(w-1, self.kernel_size[1]//r2)
out = (s[:,:,:-k1,:-k2]-s[:,:,:-k1,k2:]-s[:,:,k1:,:-k2]+s[:,:,k1:,k2:])/(k1*k2)
out = torch.nn.functional.interpolate(out, scale_factor=(r1,r2))
else:
n, c, h, w = x.shape
s = x.cumsum(dim=-1).cumsum_(dim=-2)
s = torch.nn.functional.pad(s, (1,0,1,0)) # pad 0 for convenience
k1, k2 = min(h, self.kernel_size[0]), min(w, self.kernel_size[1])
s1, s2, s3, s4 = s[:,:,:-k1,:-k2],s[:,:,:-k1,k2:], s[:,:,k1:,:-k2], s[:,:,k1:,k2:]
out = s4+s1-s2-s3
out = out / (k1*k2)
if self.auto_pad:
n, c, h, w = x.shape
_h, _w = out.shape[2:]
# print(x.shape, self.kernel_size)
pad2d = ((w - _w)//2, (w - _w + 1)//2, (h - _h) // 2, (h - _h + 1) // 2)
out = torch.nn.functional.pad(out, pad2d, mode='replicate')
return out
class LocalInstanceNorm2d(nn.Module):
def __init__(self, num_features, eps=1e-5, momentum=0.1,
affine=False, track_running_stats=False):
super().__init__()
assert not track_running_stats
self.affine = affine
if self.affine:
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
else:
self.register_parameter('weight', None)
self.register_parameter('bias', None)
self.avgpool = AvgPool2d()
self.eps = eps
def forward(self, input):
mean_x = self.avgpool(input) # E(x)
mean_xx = self.avgpool(torch.mul(input, input)) # E(x^2)
mean_x2 = torch.mul(mean_x, mean_x) # (E(x))^2
var_x = mean_xx - mean_x2 # Var(x) = E(x^2) - (E(x))^2
mean = mean_x
var = var_x
input = (input - mean) / (torch.sqrt(var + self.eps))
if self.affine:
input = input * self.weight.view(1,-1, 1, 1) + self.bias.view(1,-1, 1, 1)
return input
def replace_layers(model, base_size, fast_imp, **kwargs):
for n, m in model.named_children():
if len(list(m.children())) > 0:
## compound module, go inside it
replace_layers(m, base_size, fast_imp, **kwargs)
if isinstance(m, nn.AdaptiveAvgPool2d):
pool = AvgPool2d(base_size=base_size, fast_imp=fast_imp)
assert m.output_size == 1
setattr(model, n, pool)
if isinstance(m, nn.InstanceNorm2d):
norm = LocalInstanceNorm2d(num_features=m.num_features, eps=m.eps, momentum=m.momentum, affine=m.affine, track_running_stats=m.track_running_stats)
norm.avgpool.base_size = base_size # bad code
norm.avgpool.base_size = fast_imp
setattr(model, n, norm)
class Local_Base():
def convert(self, *args, **kwargs):
replace_layers(self, *args, **kwargs)
imgs = torch.rand(train_size)
with torch.no_grad():
self.forward(imgs)
class HINetLocal(Local_Base, HINet):
def __init__(self, *args, base_size, fast_imp=False, **kwargs):
Local_Base.__init__(self)
HINet.__init__(self, *args, **kwargs)
self.convert(base_size=base_size, fast_imp=fast_imp)
class MPRNetLocal(Local_Base, MPRNet):
def __init__(self, *args, base_size, fast_imp=False, **kwargs):
Local_Base.__init__(self)
MPRNet.__init__(self, *args, **kwargs)
self.convert(base_size=base_size, fast_imp=fast_imp)