Manipulate Gradient
The section includes some technologies related to gradient descent optimization method.
Gradient Clipping
A good explanation: What is Gradient Clipping?
Related paper: Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity (ICLR’2020)
Sometimes the training loss may not stable, it may caused by exploding problem. A simple yet effective way is to use the Gradient Clipping method.

Implemented by PyTorch [document]
# inside the training loop
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm_value) # add this line
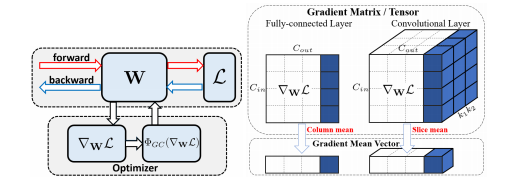
optimizer.step()Gradient Centralization (ECCV’20)
Paper: Gradient Centralization: A New Optimization Technique for Deep Neural Networks
It normalizes the gradient to zero mean that can speed up the training process and increase the generalization ability (see the repository).
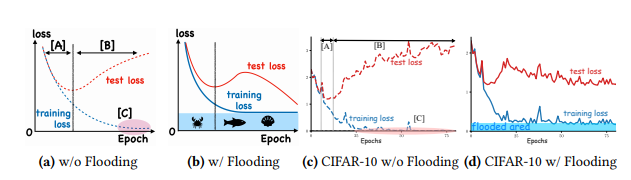
Gradient Flooding (ICML’20)
Paper: Do We Need Zero Training Loss After Achieving Zero Training Error?
It sets a threshold for the training loss. If the loss is lower than the threshold, the method will penalize the overflowing value to avoid overfitting.
Just adding one line of code (PyTorch) to implement it:
outputs = model(inputs)
loss = criterion(outputs, labels)
flood = (loss-b).abs()+b # This is it!
optimizer.zerograd()
flood.backward()
optimizer.step()Enhance the Basic Operation
This section focuses on the basic operations in CNNs, e.g., convolutional layer, pooling layer, etc.
Anti-aliasing (ICML’19)
Paper: Making Convolutional Networks Shift-Invariant Again [code]
Down-sampling feature map with stride convolution and pooling process usually causes alising problem. The paper presents a solution to remit the problem.

## installation (bash)
pip install antialiased-cnns
## usage (python)
C = 10 # example feature channel size
blurpool = antialiased_cnns.BlurPool(C, filt_size=4, stride=2) # BlurPool layer; use to downsample a feature map
ex_tens = torch.Tensor(1,C,128,128)
print blurpool(ex_tens).shape # 1xCx64x64 tensorLearning Rate
This section includes some useful strategy of learning rate. For example, the scheduler, optimizer, etc.
Cosine Scheduler (ICLR’17)
Paper: SGDR: Stochastic Gradient Descent with Warm Restarts
The learning rate is designed with cosine annealing strategy. An implementation can be found at Link that is original from GitHub.
Usage:
# warm_up_with_cosine_lr
model = ...
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-5) # lr is min lr
scheduler = CosineAnnealingWarmUpRestarts(optimizer, T_0=250, T_mult=2, eta_max=0.1, T_up=50)
for epoch in range(n_epoch):
train()
valid()
scheduler.step()An example: CosineAnnealingWarmUpRestarts(optimizer, T_0=150, T_mult=1, eta_max=0.1, T_up=10, gamma=0.5)
